



提前庆祝要解封啦~~~
突然接到老大的电话,最近实习公司的项目需要将项目中的中文全国际化(
中英其他语言切换),让我在家处理一下。
此时艰巨而光荣的任务交给我啦~~记录下啦啦啦
开始的碰壁
项目的功能基本上都完成了,剩下的听老大说未来只剩一些新的页面功能新增。现在需要把现在能看见的中文全国际化,转为英文,要去前端的 Vue 文件里面,找到这些中文,然后用 Vue 的 i18n 去做语言切换,显示不同的语言。
本来以为是一个小的任务,做的时候发现头疼了。
- 项目已经大体上完成了,要处理的文件toooooo多,最后代码跑完(
后面的小工具)最后处理了8k+的文件。 - 中文分布的很广,在前端各种标签里,有按钮标签、有表格标签、有文本标签等等等…需要将这些中文全拎出来处理。
- 中文干扰项,如中文注释。
- 多国语言翻译的问题…不过老大和我说用翻译软件把中文翻译出来就行。
- 隐藏的一些任务…并不只是只有.vue文件里面有那些中文,在js文件里面也藏着一些中文需要处理,要处理的并不只有vue文件…
- 一些烦人但又避免不了的问题,比如…i18n的别名命名…脑瓜子疼疼的。
解决问题
当时人工处理了些文件,一是工作量的问题,二是由工作量导致效率问题。本着高效干活的我,决定跑脚本。
- 读取文件
- 获得中文数据
- 翻译
- 写入 i18n 文件
- 替换文件中的中文,用 i18n
哦吼,Python干这玩意太合适了,实在是太合适了。
撸起袖子开干!,反正在家里,嘿嘿嘿
python读取文件
直接上代码,这个很简单,就是递归文件夹,将文件夹里面指定的文件后缀提取出来。
# coding:utf-8
import os
listFileName = []
# 获得后缀是.vue的文件名
def getFileName(path):
files = os.listdir(path) # 获取当前目录的所有文件及文件夹
for file in files:
try:
# 获取绝对路径
file_path = os.path.join(path, file)
# 判断是否是文件夹
if os.path.isdir(file_path):
# 如果是文件夹,就递归调用自己
getFileName(file_path)
else:
extension_name = os.path.splitext(file_path) # 将文件的绝对路径中的后缀名分离出来
if extension_name[1] == '.vue':
listFileName.append(file_path)
except:
continue
return listFileName
# 获得文本信息
def readHTML(fileName):
html = open(fileName, 'r',encoding="utf-8").read()
return html
def getFileTrueName(filePath):
return os.path.basename(filePath).split('.')[0]
# 写入文件
def write(JsonResult,inputFilePath):
f = open(inputFilePath, 'w',encoding="utf-8")
f.write(JsonResult)
f.close()
获得中文数据
如我在开头写的那样,这个是最头疼的地方。中文分布的很广,在前端各种标签里,有按钮标签、有表格标签、有文本标签等等等…需要将这些中文全拎出来处理。
本来以为就是一个匹配中文正则表达式的问题,做的时候又遇到拦路虎…中文注释是不需要翻译的,需要排除掉注释内容…
中间写的很多版,删删改改,最后使用了策略模式来完成这个获得中文数据的功能。
类图如下
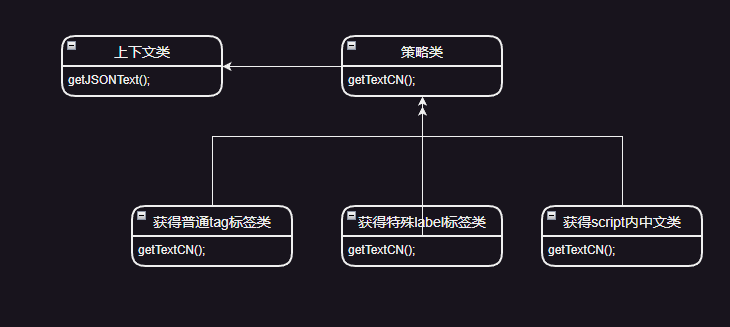
代码如下
# coding:utf-8
import pinyin
import re
import os
# 策略类父类
class TextSuper:
def getTextCN(self, label, html):
pass
# 获得tags中文子类
class TagsCN(TextSuper):
def getTextCN(self, tag, html):
CNTexts = []
resultList = []
# 排除注解
html = unNode(html)
pat = r"<" + tag + r".*>.*</" + tag + ">"
patSearch = r"<" + tag + r".*>(.*)</" + tag + ">"
tagHtmls = re.findall(pat, html)
for tagHtml in tagHtmls:
CNHtmls = re.search(patSearch, tagHtml)
if CNHtmls:
flag = re.match(r'[\u4e00-\u9fa5]', CNHtmls.group(1))
if flag:
CNTexts.append(CNHtmls.group(1))
# 去重
resultList = list(set(CNTexts))
return resultList
# 获得labels中文子类
class LabelsCN(TextSuper):
def getTextCN(self, label, html):
CNTexts = []
resultList = []
# 排除注解
html = unNode(html)
pat = r'[^:]' + label + r'=[\"|\'][^\"]*[\"|\']'
patSearch = r'[^:]' + label + r'=[\"|\']([^\"]*)[\"|\']'
# 获得那整行
labelHtmls = re.findall(pat, html)
for labelHtml in labelHtmls:
CNHtmls = re.search(patSearch, labelHtml)
if CNHtmls:
flag = re.match(r'[\u4e00-\u9fa5]', CNHtmls.group(1))
if flag:
CNTexts.append(CNHtmls.group(1))
# 去重
resultList = list(set(CNTexts))
return resultList
# 获得script中文子类
class ScriptCN(TextSuper):
def getTextCN(self, script, html):
CNList = []
resultList = []
# 排除注解
html = unNode(html)
scriptAllHtml = re.findall(r'<script>[\w\W]*<\/script>', html)
pat = script + r'[:|\(|\'|\"|= ]+[^;|^)|^\"|^}|,]*[)|\"|\']'
patSearch = script + r'[:|\(|\'|\"|=| ]+([^;|^)|^\"|^}|,]*)[)|\"|\']'
for html in scriptAllHtml:
scriptHtmls = re.findall(pat, html)
for scriptHtml in scriptHtmls:
CNHtmls = re.search(patSearch, scriptHtml)
if CNHtmls:
flag = re.findall(r'[\u4e00-\u9fa5]', CNHtmls.group(1))
if flag:
CNList.append(CNHtmls.group(1))
# 去重
resultList = list(set(CNList))
return resultList
# 上下文类
class Context:
def __init__(self, text_super):
self.text_super = text_super
def GetJsonText(self, label, html):
return self.text_super.getTextCN(self, label, html)
# 获得除注释外的全部中文
def getAllCN(html):
resultList = []
# 中文结果集
CNList = []
# 获得那整行
tdData = re.findall(r"[\u4e00-\u9fa5,:]+<", html)
for html in tdData:
datas = re.search(r"([\u4e00-\u9fa5,:]+)<", html)
if datas:
data = datas.group(1)
CNList.append(str(data))
# 去重
resultList = list(set(CNList))
return resultList
# 排除注释
def unNode(html):
unNotes = re.sub(r'//.*', "", html)
unNotes = re.sub(r'/?\*.*\*/', "", unNotes)
unNotes = re.sub(r"<!--.*-->", "", unNotes)
return unNotes
# 获得大写拼音开头
def getStrAllAplha(str):
jsonKey = ""
Aplha = pinyin.get_initial(str, delimiter="").upper()
jsonKeyList = re.findall(r'[A-Z]+', Aplha)
for key in jsonKeyList:
jsonKey += key
return jsonKey
# 获得Json的Key
def getJsonName(filePath):
fileName = os.path.basename(filePath)
fileName = fileName.split('.')[0]
return fileName
翻译
现在中文已经拿出来了,需要再将中文翻译到其他语言,直接调用翻译API。
有使用百度的,但是百度需要账号同时还有日请求量限制…用了会就没用百度的了,改用有道的。
代码如下
# encoding:utf-8
import urllib.request
import urllib.parse
import json
import random
import hashlib
from fileCommon import operationFile
import time
# 文件目录
dataPath = r"/Users/penglei/PycharmProjects/CreateVuei18n/createVuei18n/js/html-label.js"
# 导出文件目录
savePath = r"/Users/penglei/PycharmProjects/CreateVuei18n/createVuei18n/js/html-label-en.js"
def fanyiDict(labelJson):
index = 1
for data in labelJson:
if isinstance(labelJson[data], dict):
for k in labelJson[data]:
print("第" + str(index) + "个")
print("开始翻译值" + labelJson[data][k])
en = youdao_translate(labelJson[data][k])
print("翻译成功,结果为" + en)
# time.sleep(1)
labelJson[data][k] = en
bJson = json.dumps(labelJson, ensure_ascii=False, sort_keys=True, indent=2)
return bJson
def main():
html = operationFile.readHTML(dataPath)
labelJson = json.loads(html)
bJson = fanyiDict(labelJson)
# 写入文件
operationFile.write(bJson, savePath)
def youdao_translate(content):
key = content
ts = str(time.time() * 1000)
salt = ts + str(random.randint(1, 10))
sign = hashlib.md5(('fanyideskweb' + key + salt + 'Nw(nmmbP%A-r6U3EUn]Aj').encode('utf-8')).hexdigest()
'''有道翻译'''
youdao_url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
data = {}
# 调接口时所需参数,看自己情况修改,不改也可调用
data['i'] = content
data['from'] = 'AUTO'
data['to'] = 'AUTO'
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['salt'] = salt
data['sign'] = sign
data['doctype'] = 'json'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['action'] = 'FY_BY_CLICKBUTTION'
data['typoResult'] = 'false'
data = urllib.parse.urlencode(data).encode('utf-8')
# 发送翻译请求
youdao_response = urllib.request.urlopen(youdao_url, data)
# 获得响应
youdao_html = youdao_response.read().decode('utf-8')
target = json.loads(youdao_html)
# 取出需要的数据
trans = target['translateResult']
ret = ''
for i in range(len(trans)):
line = ''
for j in range(len(trans[i])):
line = trans[i][j]['tgt']
ret = line
return ret
if __name__ == '__main__':
main()
替换文件中的中文,用 i18n
最后一步,替换掉!齐活
代码如下
# coding:utf-8
from fileCommon import operationFile
from textCommon import operationText
import json
import re
jsonPath = r"C:\Users\Administrator\PycharmProjects\pythonProject\front\label.js"
pathRoot = r'C:\Users\Administrator\Desktop\frontCopy\src'
def myprint(d):
for k, v in d.items():
if isinstance(v, dict):
myprint(v)
else:
print("{0} : {1}".format(k, v))
def openJSON(jsonPath):
# 获得json文件
jsonScript = open(jsonPath, 'r', encoding="UTF-8").read()
return jsonScript
def openOneFormat(jsonScript):
# 转换json文件
json_data = json.loads(jsonScript)
fileNameList = operationFile.getFileName(pathRoot)
for fileName in fileNameList:
# 获得文本
html = operationFile.readHTML(fileName)
# 提取全部中文信息
# datas = operationText.getScript(html)
fileBaseName = operationText.getJsonName(fileName)
print("开始操作文件名为" + fileBaseName)
for key in json_data:
str1 = "label=\"" + json_data[key] + "\""
str2 = "label=\'" + json_data[key] + "\'"
str3 = ":label=\"$t('label." + key + "')" + "\""
print("开始将---" + str1 + "\n替换为---" + str3)
print("开始将---" + str2 + "\n替换为---" + str3)
html = re.sub(str1, str3, html)
html = re.sub(str2, str3, html)
operationFile.write(html, fileName)
# print(html)
def opensFormatAll(jsonScript):
# 转换json文件
json_data = json.loads(jsonScript)
fileNameList = operationFile.getFileName(pathRoot)
for fileName in fileNameList:
# 获得文本
html = operationFile.readHTML(fileName)
# 提取全部中文信息
# datas = operationText.getScript(html)
fileBaseName = operationText.getJsonName(fileName)
# print("开始操作文件名为" + fileBaseName)
for jsonData in json_data[fileBaseName]:
text = json_data[fileBaseName][jsonData]
str1 = text + "<"
str2 = "{{$t('eip." + fileBaseName + "." + jsonData + "')}}" + "<"
print("开始将---" + str1 + "\n替换为---" + str2)
html = re.sub(str1, str2, html)
# operationFile.write(html,fileName)
def main():
# 获得json文件
jsonScript = openJSON(jsonPath)
openOneFormat(jsonScript)
if __name__ == '__main__':
main()
启动类
定义需要处理tags、labels和script集合,然后脚本开跑就完事,嘿嘿嘿
# coding:utf-8
# 导入模块
from fileCommon import operationFile
import json
from textCommon import getDatas
from textCommon.operationText import *
# 输出目录
outFilePath = r"/Users/penglei/PycharmProjects/CreateVuei18n/createVuei18n/js/html-label.js"
# 文件目录
pathRoot = r'/Users/penglei/Desktop/work/web/manage'
# tags集合
tags = ['el-button', 'span', 'el-dropdown-item', 'th', 'el-tag' , 'th', 'td', 'label']
# labels集合
lables = ['placeholder', 'title', 'content', 'label']
# script集合
scripts = ['error','message','warning','success','value','title']
def main():
# 传入集合和策略类
resultMapDict = getDatas.getDatas(pathRoot, tags, TagsCN)
bJson = json.dumps(resultMapDict, ensure_ascii=False, sort_keys=True, indent=2)
# 写入文件
operationFile.write(bJson, outFilePath)
if __name__ == '__main__':
main()
评论区