



用在微信机器人,放在群里,通过相应的指令然后发送一些面试题的图片。
主要通过Python爬牛客的面经的HTML,然后获得它内容的标签,再将HTML文件转为图片。
1、导包
import imgkit
import urllib.request
from bs4 import BeautifulSoup
import random
import ssl
import json
2、安装wkhtmltopdf
https://wkhtmltopdf.org/downloads.html
相关参考
3、开爬
步骤嘛
- 进Java面经模块
- 随便点自己想看的板块
- 卷人家的面经
嗯,大概也就这三步
3.1、扣关键数据

嗯~,直接拿的JSON,访问他接口地址拿数据就好了
哟西,HTTPS,代码得加个SSL,齐活
还有page=1,分页也找到了,其他的比如tagId、companyId、phaseId和order看来不用我管。
ssl._create_default_https_context = ssl._create_unverified_context
3.2、进入列表的详情
知道了它的列表页是怎么显示数据的,接着要拿详情了。
进入它的详情页面
https://www.nowcoder.com/discuss/807743?source_id=discuss_experience_nctrack&channel=-1
观察URL,有一串数据,很明显就是它在变然后显示具体的详情。而且这个807743很明显是躲在JSON里面,再去找找这个807743。

哟西,这个也找到了,那请求URL就是
https://www.nowcoder.com/discuss/postId?source_id=discuss_experience_nctrack&channel=-1
3.3、扣具体的HTML页面
还是详情页面
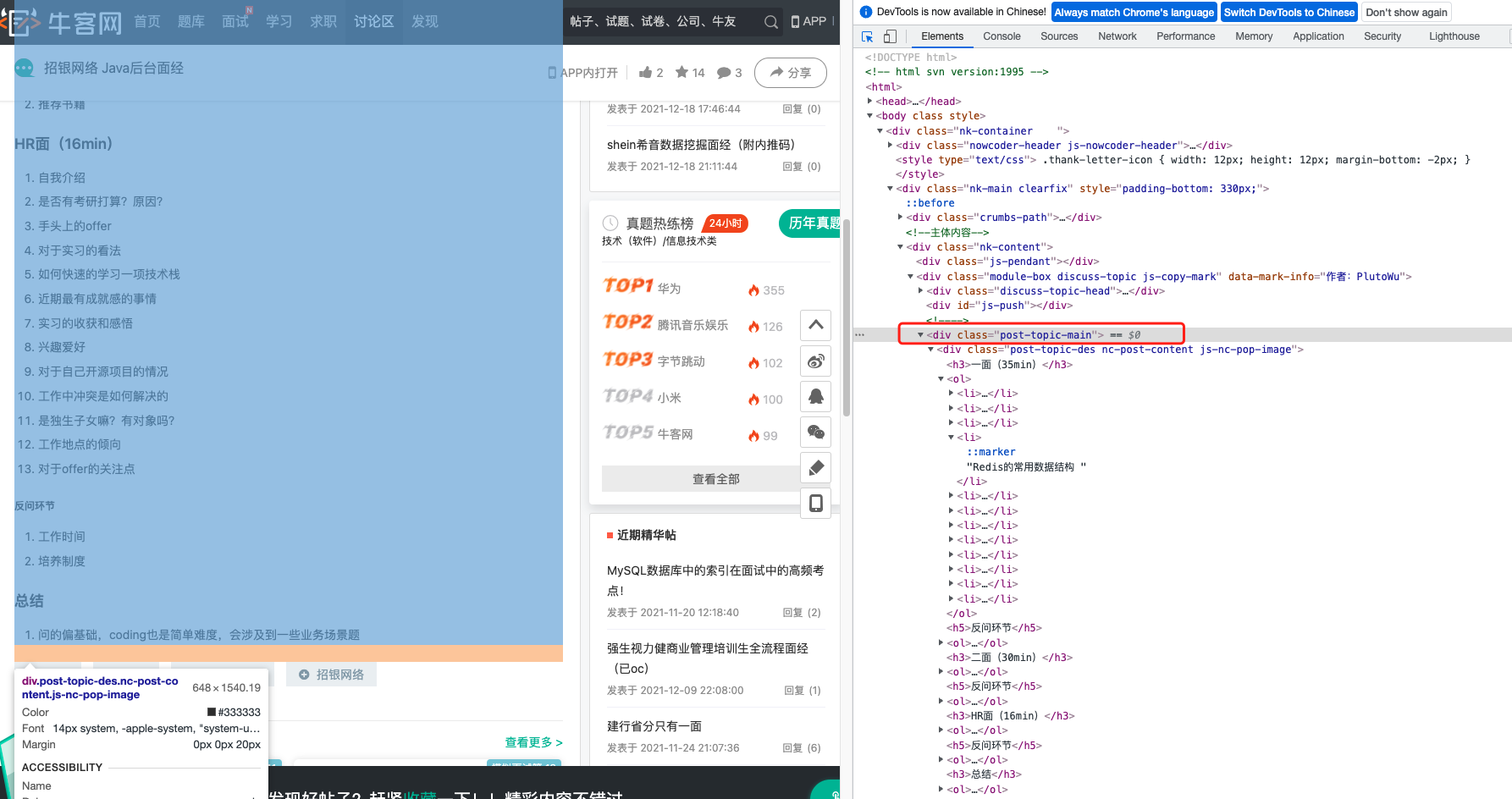
嗯~是这一块HTML,BS4 扣就完事了!
soup = BeautifulSoup(html, "html.parser")
itemSoup = soup.find("div", class_="post-topic-des nc-post-content")
再把itemSoup写入文件,齐活
with open(filename, 'w', encoding="utf-8") as file_object:
file_object.write(str(itemSoup))
4、HTML转图片
这里代码就简单了,属于面向API Demo编程
# 工具路径
path_wkimg = r'wkhtmltoimage.exe'
cfg = imgkit.config(wkhtmltoimage=path_wkimg)
options = {'encoding': 'utf8'}
imgkit.from_file(path, file_name, config=cfg, options=options)
5、开往号子吃公家饭的列车,启动!
先看看效果
5.1、HTML文件
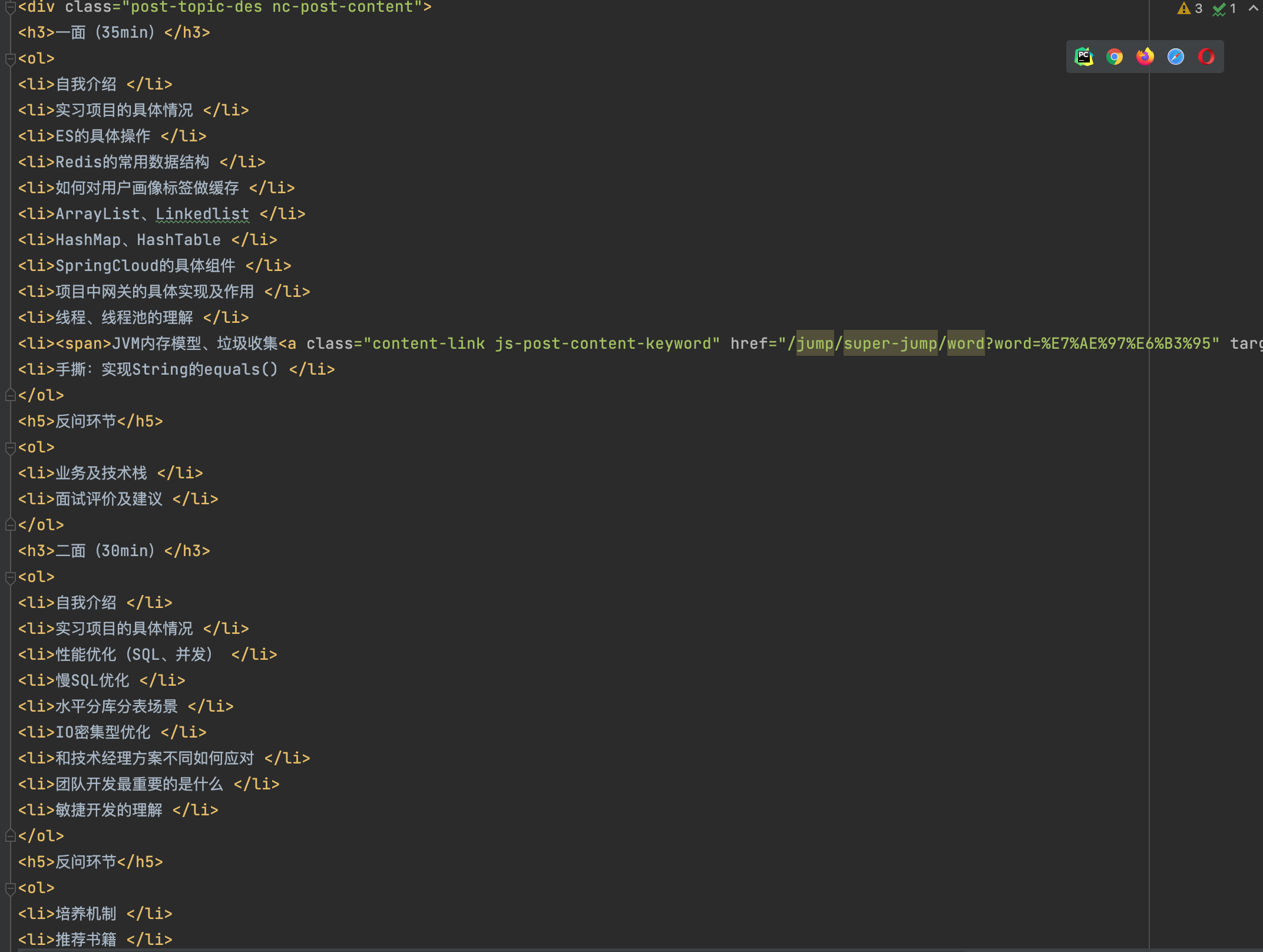
八错,八错
5.2、图片文件

很清真嘛,算了,能卷就好了。
离吃公家饭进了一步。
6、24小时开卷
之前整的一个微信机器人,现在也部署在了服务器上,通过信息文本的内容执行相应的逻辑。
效果如下
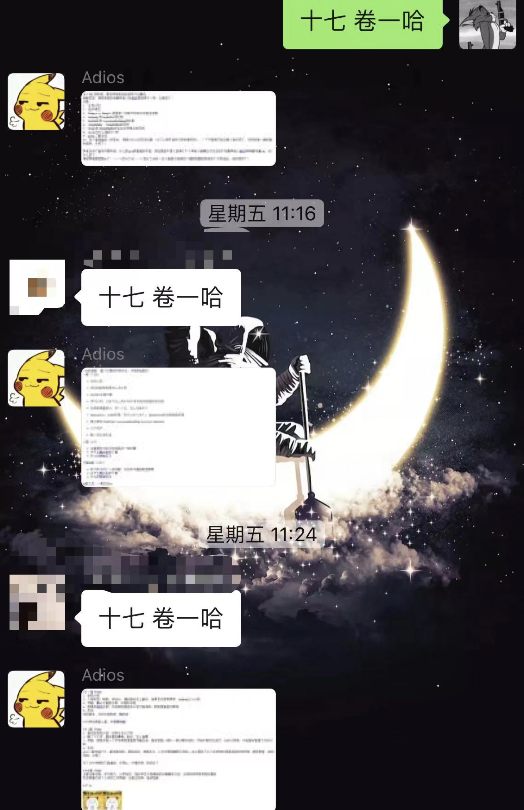
主要代码
import ssl
import random
import urllib.request
from bs4 import BeautifulSoup
import json
def nowCoderSpider():
page = random.randint(1, 99)
baseUrl = "https://www.nowcoder.com/discuss/experience/json?token=&tagId=639&companyId=0&phaseId=0&order=3&query=&page=" + str(
page) + "&_=1639388770547"
head = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
ssl._create_default_https_context = ssl._create_unverified_context
request = urllib.request.Request(baseUrl, headers=head)
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
jsonDict = json.loads(html)
data = jsonDict["data"]
discussPostsList = data["discussPosts"]
discussPostsList = filterList(discussPostsList)
discussPosts = random.choice(discussPostsList)
baseUrl = "https://www.nowcoder.com/discuss/" + str(
discussPosts['postId']) + "?source_id=discuss_experience_nctrack&channel=-1"
request = urllib.request.Request(baseUrl, headers=head)
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
soup = BeautifulSoup(html, "html.parser")
itemSoup = soup.find("div", class_="post-topic-des nc-post-content")
filename = "r'nowcoder.html"
with open(filename, 'w', encoding="utf-8") as file_object:
file_object.write(str(itemSoup))
htmlToJpg(filename)
def htmlToJpg(path):
# 工具路径
path_wkimg = r'wkhtmltoimage.exe'
cfg = imgkit.config(wkhtmltoimage=path_wkimg)
options = {'encoding': 'utf8'}
imgkit.from_file(path, r'nowcoder.jpg', config=cfg, options=options)
啊,距离吃公家饭又近了一步
评论区